
Part 2: Why Kubernetes?, Kubernetes Starter
Written August 23rd, 2024 by Nathan Frank

Photo source byBoliviaInteligente on Unsplash
Recap
This article picks up from the first article: Why this series? in the Kubernetes Starter series.
Know about the value Kubernetes brings? Skip to Application Starter.
What problem is Kubernetes looking to solve?
There's a lot of manual processes in conventional application deployment, Kubernetes is an automation solution that provides management of those manual processes.
To better understand the value Kubernetes brings we'll need to look at conventional application development/deployment.
Let's look at a common application deployment

This common deployment pattern has a server or VM with an operating system installed, then all the dependencies and application runtimes that are needed to run the code, and then the code. If you want to run multiple instances, it requires another VM. Possibly you could clone it.
Issues with this:
- There's two instances of the operating system using more resources than might be needed. Operating systems can bring extra resource drain, the more instances one has the less resources are going to the applications
- The code that is running on the server/VM might not be using all the resources it has, letting some go to waste. Partly mitigated if it's running on a VM cluster as other VMs might be able to use those idle resources
- To scale, we are either redeploying to scale up (larger VMs) or scale out (more VMs). With bare metal servers, buy some more
- We have to manually deploy and manage a load balancer
- If instance 1 and instance 2 both go down, the application is down until someone brings the server/VM back up
Now let's deploy another app

It's a fairly similar pattern to above. Just duplicate for additional applications.
Issues with this:
- Because the dependency and runtime versions may not be the same across applications, we can't install them in the same server/VM. If we do, then both applications become tied together and have a harder time to release due to higher dependencies; both need to be deployed together if the dependencies change.
- More lost resources to operating systems, and it gets worse the more applications/application instances one needs to run
- More lost resources to idle resources (in VM scenarios other workloads could be using the idle resources)
- We have to manually deploy and manage a load balancer per application
- If instance 1 and instance 2 both go down for an application, the application is down until someone brings the server/VM back up
How does Containerization and Kubernetes handle this differently?
Containerization

Containerization builds a container image that contains not just the application code, but also the dependencies and runtimes that are needed to run the application. Previous "it works on my machine" configuration issues are resolved as they are baked into the container image. Then an image guts deployed as a container instance and runs the service.
The server/VM running the container has the operating system installed, but can run multiple containers as long as there's enough resources. Containers are walled off from each other so they do not interact with each other or the host operating system.
In a container approach one can scale up by deploying more containers of the same image to more servers/VMs.
Benefits of this:
- The container just runs, and can run anywhere there's a container runtime
- The container has everything it needs to run all together and the same image can be deployed again and again
- You can run multiple containers on the same hardware lowering the operating system overhead
Issues with this:
- One still needs to ensure that the containers are running
- One needs to manually redeploy containers to leverage more resources
- If all containers stop responding, the application goes down
- If the server/VM the container is running on goes down, once it reboots the container runtime can restart the containers to come back online
Kubernetes leverages containerization and add orchestration
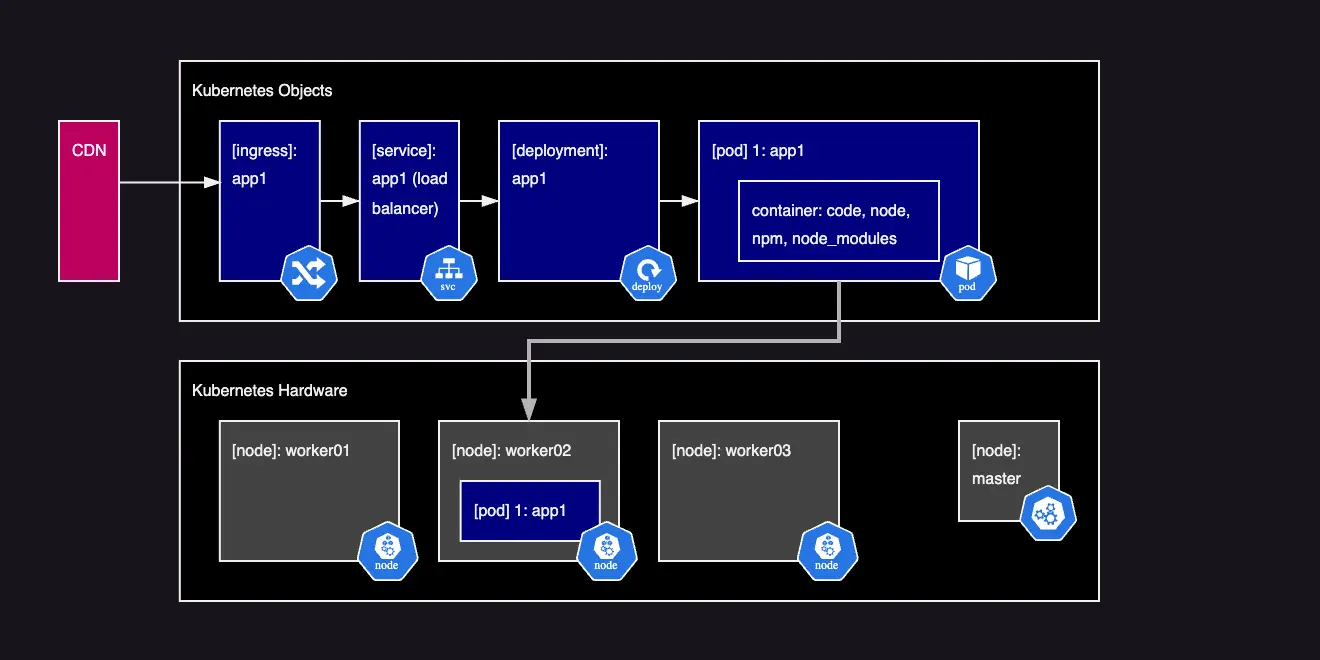
Kubernetes looks to orchestrate and manage all the aspects of the running container lifecycle.
Benefits of this:
- Kubernetes is checking to make sure the containers are running, if they stop responding containers are restarted
- Kubernetes is checking nodes to make sure they are running, if they stop responding they are rebooted and workload is shifted to other worker nodes in the cluster
- If a node needs to go down intentionally, the work can be drained from that node and redeployed to capacity on other nodes, Kubernetes manages this for us. The node can then have the OS upgrade, patching, or hardware replacement without impacting the workloads. This isn't one server per app, but a measure of capacity of the cluster and how many nodes we want to concurrently run maintenance on
- Kubernetes manages internally which containers are deployed to which worker nodes
- Kubernetes provides mechanisms for min and max replicas and can scale more containers as the demand changes over time
- Kubernetes manages all the networking to all the changing pods and workloads on nodes for us including load balancers through services
- Adding additional nodes to a cluster is trivial, and they don't need to be exactly the same
- It's super flexible. It can be a smaller cluster for a lower environment and a larger cluster in production based on workloads
- There's less resources lost to operating system overhead
Issues with this:
- In the single app, single node we only had one server/VM, here we have four, what? There's more machines, but that becomes more clear as additional workload is added. Yes, it's also possible to run a single node that is both the worker and master node for small workloads. If you are deploying a single container, Kubernetes is likely overkill for your use case. (Note: developing locally with Rancher Desktop is running a single node that runs both the control plane and the workloads)
- You typically set up a cluster of nodes that performs the workload for you, also that cluster tends to need multiple master nodes set in High Availability (HA) mode
- It's complex, but it's worth the time investment for a system that manages the complexity for us
Note: Technically the deployment creates a replicaset which creates pods and the pods run the containers we specify. replicasets are kept out of the diagrams for simplicity, but it's good to understand what's happening the full way. Also they show up with kubectl get all -n sample.
Also, deployments can have multiple containers. You might have one container that runs the application, another might check on readiness and a DB container. Depending on how you architect an application (having databases in a separate deployment has different benefits from a scaling perspective). Scaling to 2 replicas, means 2 pods with all of the containers specified.
Yes, but let's make sure there's another instance

Benefits of this:
- All of the other benefits from above.
- We were able to add more running containers by changing a single value int a deployment file.
- Some configurations can handle autoscaling the number of containers up and down as the workload shifts.
Issues with this:
- The same complexity items mentioned above.
What does it look like with multiple apps?

(Note: Some arrows omitted from previous diagrams to help focus on the pod to node mapping. All the same connections between ingress and services and deployments and pods still applies)
If worker02 node goes down the pod 1 for app 2 will likely get redeployed to worker01 node, at least until worker02 node becomes available again.
If worker01 and worker02 nodes become unavailable the workload may shift to worker03 if there's capacity for that workload. We do remain constrained by the available CPU and RAM resources.
If the master node goes down the workers can continue to run, but changes to workloads can't happen until the master becomes available again. This is typically why clusters with multiple masters (odd numbers of 3+) are created to run in High Availability (HA) mode.
Benefits of this:
- We can deploy an entirely different or similar application to the cluster in a similar manner.
- The cluster deploys and manages workloads of the applications for us.
- If we need more resources, infrastructure and development teams collaborate to determine if additional nodes are needed.
Issues with this:
- The same complexity items mentioned above.
How does Kubernetes do the orchestration?
The master node keeps track of all the objects and the state of what the cluster currently has and what it should be then initiates changes to make it match. It runs as a control plane which is the hub of the hub and spoke model to the nodes.
As nodes are joined to the K8s master they run additional K8s software that allow them to inspect their own state and update to what's been asked by the master.
When a K8s user updates a declarative file and applies it to the cluster, K8s takes a look at what it has, what its being asked to be and then updates the cluster to match. It might be a small service change, it might be to roll out an entirely new application.
Running Rancher Desktop is effectively running a single node cluster where the workload is also deployed to the master/control plane.

Command line output from a kubectl get nodes command showing a local Rancher Desktop setup having a single node that is also the control-plan and master.
Wrap up
We've now seen some of the issues with conventional application deployment and how containerization and kubernetes bring solutions to manage application deployment and scale for us.
Moving along
Continue with the third article of the series: Application Starter
This series is also available with the accompanying codebase.
Stuck with setup? Refer to full project setup instructions.
Done with the series? Cleanup the project workspace.