
Part 3: Application Starter, Kubernetes Starter
Written August 23rd, 2024 by Nathan Frank

Photo source by BoliviaInteligente on Unsplash
Recap
This article picks up from the second article: Why Kubernetes? in the Kubernetes Starter series.
Not interested in the Application Starter? Skip to Containerization.
Applications concepts
As we jump in we'll assume that readers know how to build web applications.
Which application, what does it do, what language is it in, what security measures do you add in? There are tons of answers to these questions and most of them we'll leave up to the reader to decide. You know your application, your domain better than anyone else and that knowledge needs to be taken into account.
In this case we'll start with a node.js API application. It's got an eslint configuration, and a swagger API explorer integration.
The example we use could be anything really: python, java, .NET, go, rust. Why js and not ts? This example is about taking an existing application and deploying to K8s. Why js and not ts? This example is about taking an existing application and deploying to K8s. Why does it do so little? Let's keep the dependencies low to focus on the K8s aspect.
There are a few that we'll talk about early on
- Secret management
- Automation test strategy
- Accessibility
- Documentation
Secret management
There's various kinds of configuration, here's a few:
- Configs: What API endpoint should this app reach out to? What internal port should the application listen on?
- Feature flags: Should "Feature A" be currently configured to be on or off?
- Secrets: What is the username and password of the database?
Secrets are the most dangerous as they can be abused to gain access to other systems behind the scenes.
If an application isn't built with secrets in mind, they will be added into the repository, likely in plain text/unencrypted.
Too often orgs give all developers access to all code repositories as it prevents access issues and allows work to continue. Attackers can use dark web exposed username/password dumps to find anyone in the org and get entire repositories of code... and they do this not just to see what kind of weaknesses, but because many teams expose secrets in codebases.
Locking down access to specific repositories is better for security and lowers the amount of people that have access, at the cost of speed to access for teams. Attackers now need to not just find a developer with a weak username/password to exploit, they have to find one with the access to the repository they want, a much harder feat. While you are at it, turn on MFA and consider code check in signing.
(Checkout the podcast: Darknet Diaries for all sorts of cyber security stories)
Automation test strategy
Applications need to iterate. New features are added. New security holes are found and patched across OSs, dependencies, and platforms. All these things require regression testing.
Manual testing is expensive and time intensive, slowing down an orgs ability to pump out new features. If we automate this process then we shift quality left (earlier in the process), release with confidence, and release more frequently.
In the world of Digital Business Transformation (DBT), digital startups are blazing past existing old enterprises with speed to market with processes like automation.
What kinds of automation?
Unit tests:
What level of per code block testing is being done to ensure that it runs correctly? What's the coverage? Does this utility with date time functions always work consistently? If something it depends on changes does it continue to work?
Do lots of unit testing. Have 80% coverage at least. Reaching 100% coverage may not be achievable or might be cost prohibitive.
End to End (E2E) Tests:
What kind of E2E testing ensures that features continue to work? Once a new feature is rolled out, can the user still login? Can they make the purchase they need to?
The amount of E2E tests are different for a product that doctors use to monitor life critical values than from one that allows a newsletter sign up.
Accessibility
Accessibility is critical to create experiences that can be experienced by all, beyond vision disabilities to cognitive impairments. When we make experiences accessible, we make them better for all. This requires visual design and user experience design to establish the experience patterns, developers to code it and test it and for validation of accessible aspects to be checked (both manually with screenreaders and with automated tools like Pa11y and Axe). Beyond making experiences better, WCAG 2.2 AA compliance is legally required in most cases.
Documentation
"Yeah, yeah, I'll get to (documentation)" and then it never happens. Has your development flow been interrupted by another meeting? What were you working on? How did you build this 6 months ago?
Keep in mind there's a balance to how much documentation is needed. Paragraphs per function is likely too much. Remember it's a tool for developers, ask yourself, what would I want if I was coming in cold to this and consider other levels of engineers above and below you.
Code comments
Even if you don't document everything or use conventions like javadoc/jsdoc per method, write what it was intended to do.
Make sure your build tools strip out the comments.
Readmes
Readmes stay with the codebase, if you have access to the codebase you have access to the documentation. Yes confluence, high level architectural design documents, technology solutioning, diagrams might also be needed. Put in a readme.md. Consider a contributing.md. Put the setup instructions into the codebase.
Make sure your build tools strip out the readmes, the computer doesn't need it to run.
If you haven't looked into Markdown, brush up on the basics of md.
Postman
Often a flow requires authentication, using that token to add an item to a cart, confirming the cart, and making the payment. Tools like Postman are great because they allow saving the API calls that need to be made along with the parsing of the response to create the chain of requests.
Be careful of secrets captured in Postman as they are often checked into repositories, consider a solution that externalizes secrets or at minimum has a test environment set of credentials.
Swagger
Often APIs can have minor additional documentation that is used to auto generate a swagger endpoint. It's worth doing early to serve as self testing/self documenting APIs.
Be careful not to expose swagger UI in production
Application hands on
Let's dig into the actual project
What's the application do?
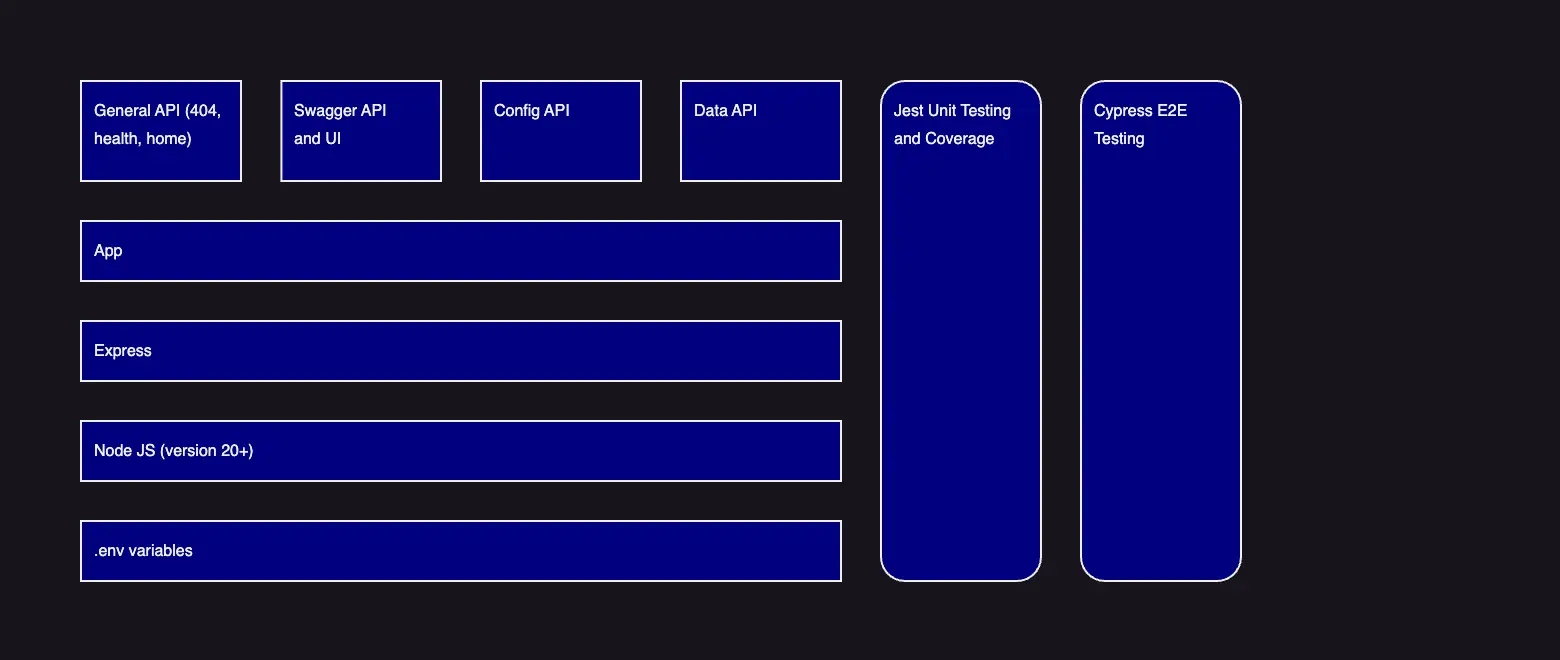
The application is a simple Node JS Express API server that contains a few endpoints running on port 3000:
/configcurrently returns JSON objects that demonstrate the configuration and secrets set in the application (NOTE: Never provide users a way to access server side secrets in production)./datacurrently returns a success, but could be added to for retrieving and storing to a database./swaggercurrently shows a swagger interface for the APIs available to the application only if configured to do so (typically swagger APIs are not exposed in production)./alive/live,/alive/ready,/alive/healthcurrently return success and are tied into for the health checks of the application.
Getting the local application working
To run the application locally:
Install nvm and node 20
(may already be installed from earlier, but if not let's make sure it is)
Install dependencies with npm
1# from the path "application/sample-node-api" 2npm installRun the task to setup a .env file
1# from the path "application/sample-node-api" 2npm run dev.create-env-file-from-templateThis copies the .end.template file that IS checked into version control to .env which is .gitignored. It has the keys one needs to run the app, but the values need to be manually dated.
Note: If you run this and have an existing .env file in the project folder, it will be lost and overwritten.
Populate the .env file with sample values that do not include "TBD"
Change the values that are in the .env file to something that doesn't contain "TBD". These will not be checked into version control because the .env file is in the .gitignore. Checking secrets into version control is a leading issue with exposing critical information.
Run the application server
1# from the path "application/sample-node-api" 2npm run start
Looking at secrets
Often the best way to handle secrets is with environmental variables. They are set on the specific machine and the application has logic on how to read them (like database usernames and passwords). Some configuration variables may also be set as environmental variables (like ports that the application runs on).
There's no way functionally to differentiate between the purpose. Consider the naming convention of env vars to assist: PRIVATE_NODE_API_DB_PASSWORD or PUBLIC_NODE_API_PORT clearly tells what the var is and if we consider it private/public. Code reviewers can pay extra attention to PRIVATE_ vars during Pull Request (PR) reviews.
In the node API application sample there's code that looks to make sure all the env variables are set at application startup time and errors out if they are not there. By not allowing the application to continue we ensure that someone configures these non optional secrets from the start.
We also see that there's a .env.template file checked in, it has dummy values set, but there's code that ensures values that contain "tbd" are rejected. This ensures that the required variables are known at application startup and the local developer variables are shared across teams.
Secrets can be handled with .env files on actual environments (via file mounts into a container), or through the management of individual ENV vars.
Note that in this scenario, .env files are .gitignored so they are not checked into the repository and there's a local command npm run dev.create-env-file-from-template (application/sample-node-api/package.json:11) that copies the template to a local .env file for the local developer to set values in.
These are some strategies to ensure that secrets are not checked into a codebase.
Looking at automation
Running unit tests
For unit tests in this instance we are using Jest tests to run the tests and also provide coverage reports.
Running the unit tests locally
Run the test
1# from the path "application/sample-node-api" 2npm run testSee the result in the command line
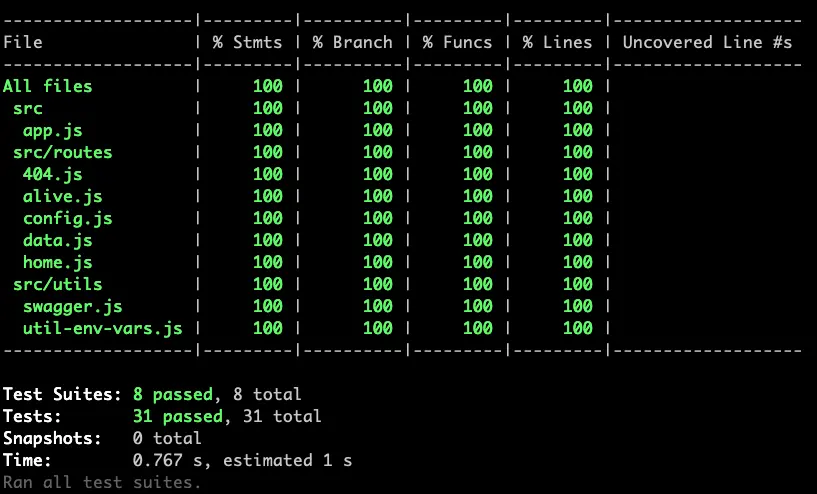
This demonstrates that all the tests are passing (8 of 8 suites and 31 of 31 tests) and that the coverage is above the threshold of 80% (in this case we are 100% across the board).
See the result in the coverage report
After running the test the following file will be generated:
application/sample-node-api/.jest/coverage/lcov-report/index.htmland can be opened in a local browser to explore the code coverage.
If coverage wasn't above 80% it helps developers to understand where the coverage is lacking on a per file basis.
Note the coverage reports are not checked into version control as they would be different every time they are run, often resulting in conflicts.
Running E2E tests
Typically E2E tests would be run against a UI project where a user would go through flows like: login or register, add an item to cart and checkout. These tests would replicate the click behavior of a person doing the activities automating the manual QA regression testing. If someone can't perform the core features, then evaluate if you can launch with that issue. In this case we are leveraging Cypress tests. There's a Cypress cloud that has some really slick offerings. For this case we are using the open source Cypress App.
The sample node api app we have just responds on a few endpoints. So we are just using cypress to validate that the API is returning with some key elements and responses. Once a UI is in place additional specs can be added to test the UI.
Running E2E tests locally
Run the command to run the local project
1# from the path "application/sample-node-api" 2npm run start.devNote: Skipping this step results in tests that will all fail as it requires the local application running to test against.
In a secondary terminal, run the CLI command to start the tests locally
1# from the path "application/sample-node-api" 2npm run test.cypress.openUse the interface to run all tests
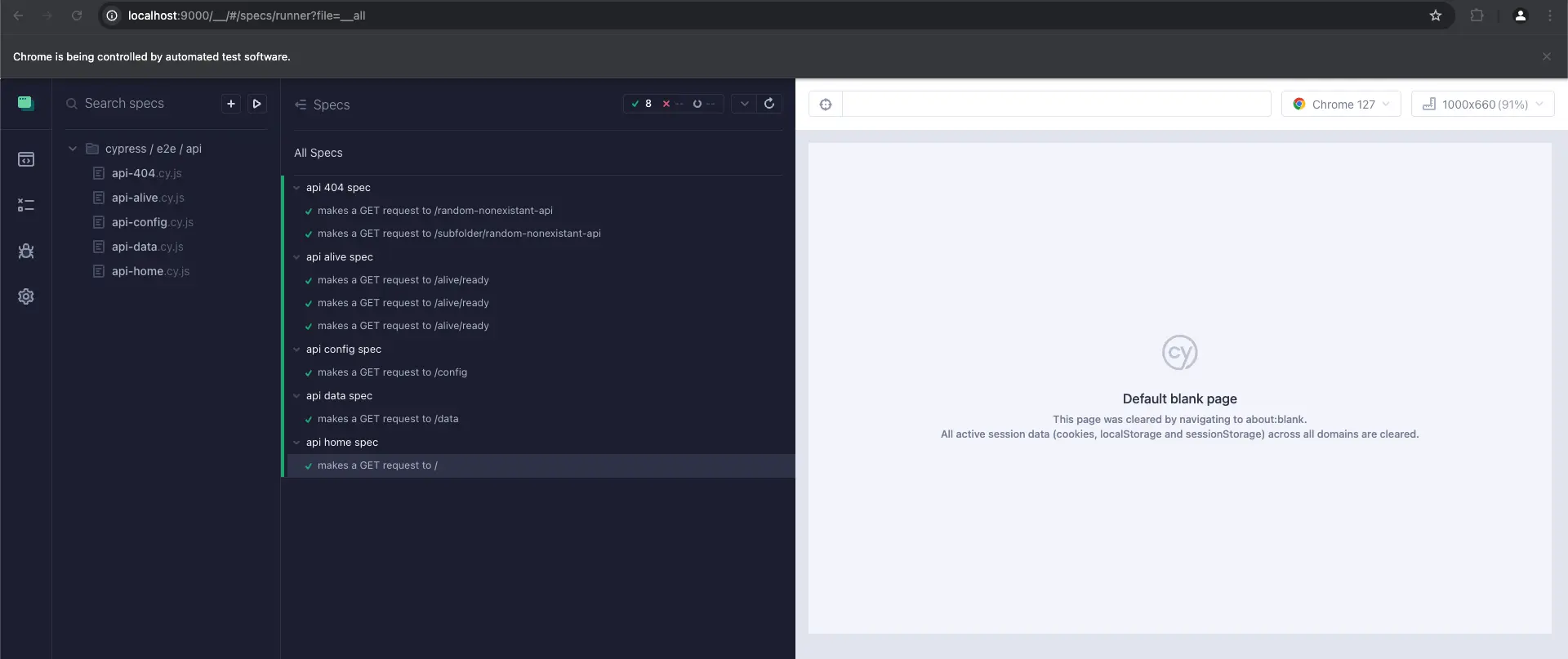
Note that the tests pass. If they were not passing additional information would be present here to help modify the tests until they pass.
Running E2E tests from the CLI
Run the CLI command to run the tests headless
1# from the path "application/sample-node-api" 2npm run test.cypress.e2e:chromeReview the output in the terminal
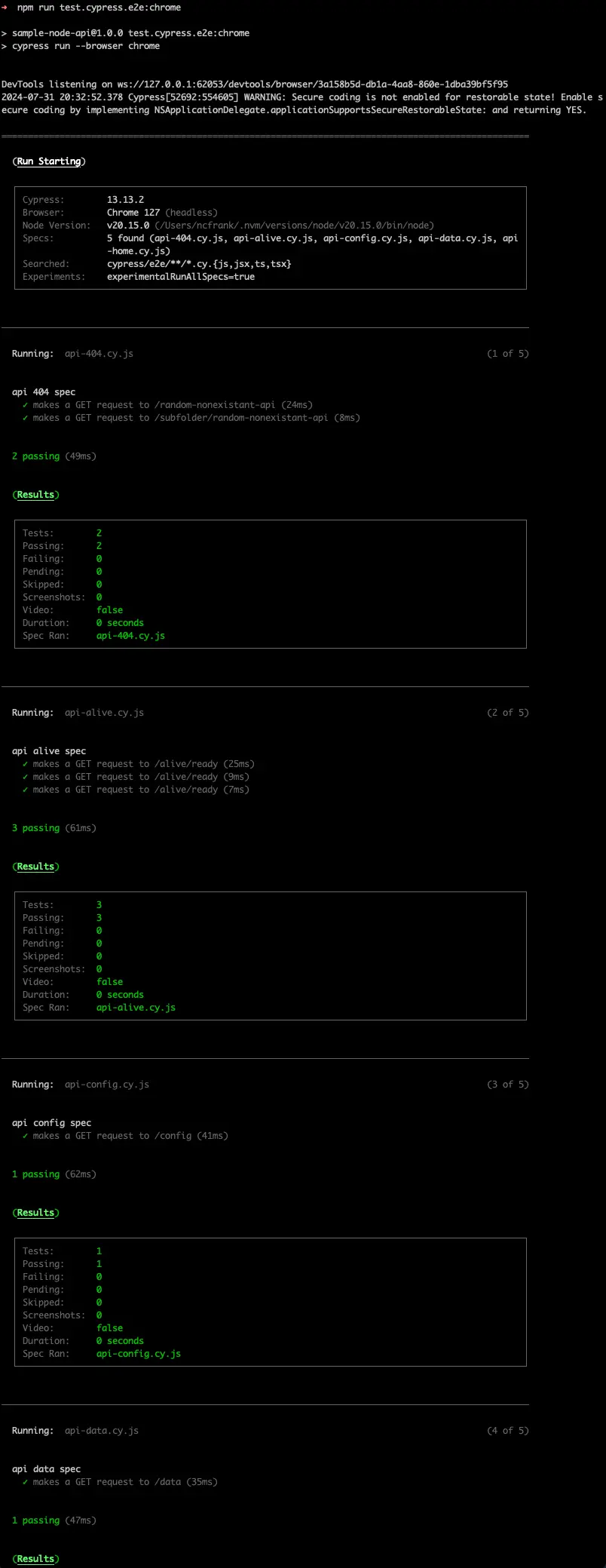
Note that the tests are passing.
Looking at Accessibility
In this case we are focusing on an API server. Currently there's no User Interface (UI). At this point in the journey there's not, but we may revisit in the future.
Resilience
When talking about application resilience the applications need:
- The ability to gracefully handle exceptions or crashes, continue to run/restart and report on issues to monitoring (needs to be handled at the application level)
- multiple instances running so if one goes down temporarily the others can handle the load (spoiler, we'll handle this with containers)
- The flexibility to move the workload to other computers during maintenance (spoiler, we'll handle this with K8s)
- The ability to move workload to other physical locations to address disaster recovery (spoiler, handled by co-location or cloud offerings, outside the scope of this series)
Performance
Planning for and including the right level of resources (CPU, RAM, Disk) is critical, but also considering scaling out: the ability for more instances of an application to come online to take on bursts in load. This has importance for architecture on how they are planned to be stateless to scale.
Having the correct caching layers in place (from redis to CDNs) can make all the difference. Ensure it's considered as part of your architecture phase. Also keep in mind how caches are invalidated for new content/updates.
Performance for a headless data pipeline application with billions of events per second (likely tested with a tool like JMeter or Postman's Newman tests) and that of an end user interface used around the world (likely tested with tools including Lighthouse-ci and Pa11y-ci). Consider putting performance tests into the CI/CD process so that it stays top of mind. Bonus points for blocking commits that take performance below thresholds. As this is focused on Kubernetes, we'll skip this aspect.
Security
This example application exposes an endpoint `/config` that lists out the actual values from the configuration INCLUDING THE SECRETS! Exposing this kind of data completely defeats the purpose of secrets: just hand the attackers your database. It's done this way so that as we move forward and see how secrets are managed we can see those values updated.
Please, please, please do not expose secrets in a codebase.
Don't even include it in lower environments because it means there's a chance it gets turned on in production.
The security within your application needs to be appropriate. Consider all the best practices including preventing SQL injection, cross site scripting (XSS), and having a penetration test performed by an outside vendor.
Build scans into your CI/CD processes that look for vulnerabilities in dependencies: Sonarqube and Synk to name a few. Then also put the processes in place to ensure they get looked at.
If you are building applications, likely you've already got this together and are following best practices, if not you've got some additional homework to do.
Wrap up
We now have an understanding of a basic application that we'll deploy with Kubernetes in the upcoming sections. We've gotten it running (npm start.dev) and were able to run unit (npm run test.unit) and E2E tests (npm run test.cypress.e2e:chrome).
Moving along
Continue with the fourth article of the series: Containerization
This series is also available with the accompanying codebase.
Stuck with setup? Refer to full project setup instructions.
Done with the series? Cleanup the project space.