
Part 5: Kubernetes and Orchestration, Kubernetes Starter
Written August 23rd, 2024 by Nathan Frank

Photo source by BoliviaInteligente on Unsplash
Recap
This article picks up from the fourth article: Containerization in the Kubernetes Starter series.
Know about Kubernetes and Orchestration? Skip to Managing Secrets with Vault.
Kubernetes and orchestration concepts
We've previously talked about the benefits (see Why Kubernetes?) provided by Kubernetes which is summed up as:
Leveraging automation in managing the state/scale of a series of applications/services while adhering to best practices in Infrastructure as Code (IaC).
Kubernetes makes it easy to deploy to and keep a cluster of machines running a series of applications/services up to date in a way that can be version controlled and peer reviewed.
Still not convinced?: Google, IBM, Groundcover, KodeCloud. Kubernetes, initially built by Google, is now open sourced. There's lots of conferences and a huge community around it.
Many of the conceptual aspects will be covered with the hands on below, but we'll call out limits and probes specifically:
Set resource limits
Make sure you set resource limits and refine these over time. You'll either have your cluster think it's running out of resources too early because the limits are set too high or have your applications crashing because they are constrained in their resources.
If you don't set limits then you have even more problems and a harder time figuring out if it is an application with a coding optimization problem or a need for more hardware and all you have are random logs that occasionally popup when there's issues.
Make sure you have startup and readiness probes
These ensure that Kubernetes knows how to classify a specific workload as up and running. There are many types of probes beyond http probes. Without them, Kubernetes will do "it's best" at guessing if your application is responsive.
There's distinction between startup, ready and liveliness probes
A few notes on Kubernetes
Working with K8s declaratively
While one can manually write all the K8s commands with the CLI and execute them or use newer K8s UI to create the objects, it's more advised to use the declarative method and check these files into version control (except for secrets).
Then you can apply them with kubectl apply -f application/sample-node-api/_devops/kubernetes/00-sample-node-api.namespace.yaml or apply an entire folder with kubectl apply -f application/sample-node-api/_devops/kubernetes/
The files will be processed alphabetically in the order of the file names. Leveraging numeric prefixes like Apache conf files allows us to ensure namespaces are created before the objects that use them.
Working with multiple K8s clusters
If one is exploring K8s and has never installed Rancher Desktop before you wont have any issue. If you've got other clusters that you have kubectl tied into you'll likely need to merge those configs and be able to switch between contexts so you can go back and forth between multiple clusters.
There have been multiple, great, articles) on how to do it as well as the official documentation on it. A kubeconfig file contains a user to context and cluster to context mapping. Switching between contexts allows accessing different clusters as different users.
Kubernetes hands on
This single article on Kubernetes doesn't go into nearly enough detail to understand Kubernetes in depth, but it provides the initial high level to get one's feet wet with the concepts and start to dig into second level concepts.
Our sample application
Our sample application requires multiple Kubernetes objects:
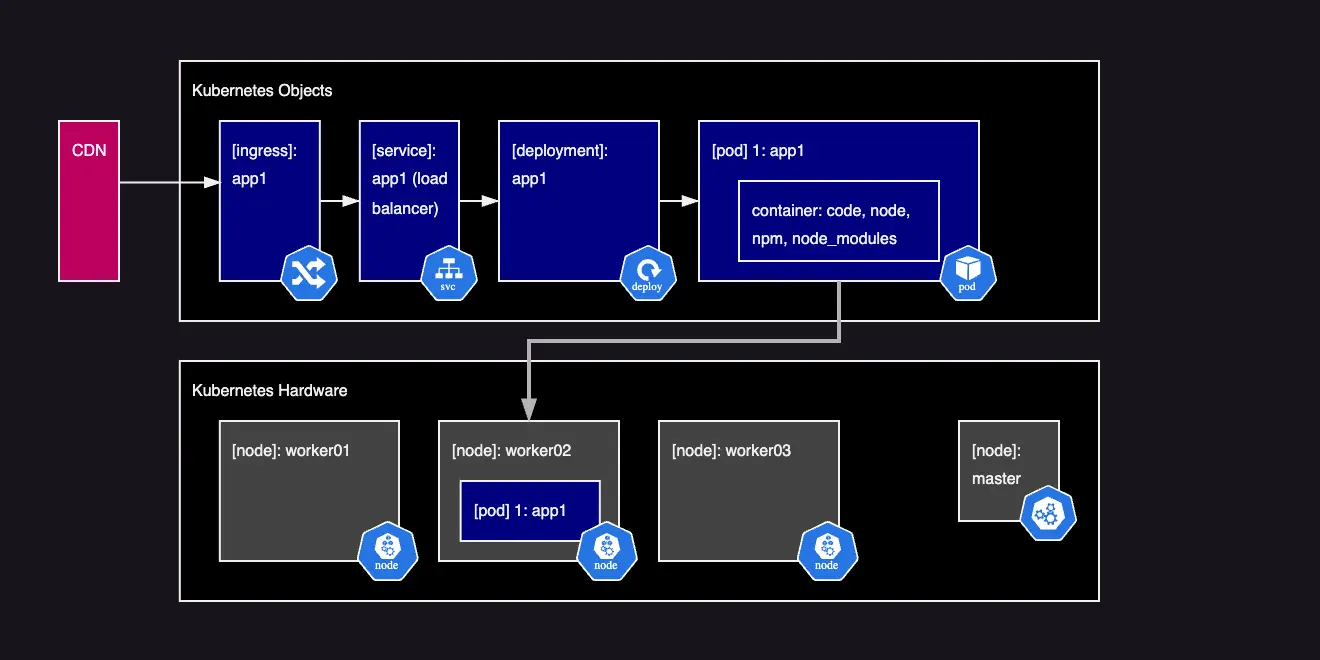
This figure depicts our sample API application running in a container and on a Kubernetes cluster. We'll go through these objects coming up and break them down.
Namespaces
K8s Namespaces help set boundaries between sets of resources in a K8s cluster. Out of the box there's the default namespace. This prevents resources from reaching out across namespaces.
Always ensure you are using a custom namespace and not the default, you never know what other objects will be in the same cluster.
Add them declaratively with:
1# application/sample-node-api/_devops/kubernetes/00-sample-node-api.namespace.yaml
2apiVersion: v1
3kind: Namespace
4metadata:
5 name: sample
6 labels:
7 name: sampleNotes on the above:
- name:
sampleis the actual namespace value
When running kubectl commands you'll need to add -n sample to make sure the command queries only that space: kubectl get all -n sample
For this series we'll assume the namespace sample (and later others for different envs like: sample-dev) . As we have a mix of Kubernetes and Helm resources, we're adding them in deploy scripts via command line so that the deploy can leverage kubectl apply -f ./kubernetes and uninstall can leverage kubectl delete -f ./kubernetes without deleting object managed by Helm.
Helpful commands (sample is a specific namespace used in this series):
kubectl get namespaceto list out all namespaceskubectl get all -n sampleto get "all" (common) objects that relate to the sample namespacekubectl delete namespace sampleto delete a namespace, also deletes all objects tied to the namespace. (Note this can cause hanging references when a tool like Helm manages Kubernetes objects; use Helm uninstall first to prevent objects stuck "finalizing")
Pods
K8s Pods are what we want. They are the actual instances of the running containers in K8s, but... we don't want to make them directly. We want Kubernetes to perform the orchestration to make sure we have the right pods at the right time.
In this series we will not directly create pod objects and instead leverage declarative files.
Helpful commands ([podname] is a specific pod identifier):
kubectl get pods -n sampleto get all pods in the namespace samplekubectl describe pod [podname] -n sampleto get details on a specific pod name [podname] in the namespace samplekubectl log [podname] -n sampleto get the logs of a specific pod name [podname] in the namespace samplekubectl exec -it -n sample [podname] -- /bin/bashto connect to a specific pod with name [podname] in the namespace sample (note /bin/bash not available on all containers)
Deployment
Kubernetes Deployments are used to ensure that a specific pod with a container is up and running with the required number of replicas through leveraging health and liveliness checks. It takes care of deploying a new pod(s) with an updated deployment or to ensure that pods are restarted with the latest secret update.
Note: Stateful sets are also helpful and there's a decision on when to use them compared to deployments. In this stateless scenario, we're using deployments.
1# application/sample-node-api/_devops/kubernetes/02-sample-node-api.deployment.yaml
2apiVersion: apps/v1
3kind: Deployment
4metadata:
5 name: sample-app-node-api-deployment
6 namespace: sample
7 labels:
8 app: sample-app-node-api
9spec:
10 replicas: 1
11 selector:
12 matchLabels:
13 app: sample-app-node-api
14 template:
15 metadata:
16 labels:
17 app: sample-app-node-api
18 app.kubernetes.io/name: sample-app-node-api
19 spec:
20 containers:
21 - name: sample-app-node-api
22 image: kubernetes-samples/sample-node-api
23 imagePullPolicy: Never
24 ports:
25 - containerPort: 3000
26 env:
27 - name: PUBLIC_NODE_API_DB_HOST
28 valueFrom:
29 configMapKeyRef:
30 name: sample-app-node-api-configmap
31 key: public_node_api_db_host
32 - name: PUBLIC_NODE_API_DB_PORT
33 valueFrom:
34 configMapKeyRef:
35 name: sample-app-node-api-configmap
36 key: public_node_api_db_port
37 - name: PUBLIC_NODE_API_DB_TABLE
38 valueFrom:
39 configMapKeyRef:
40 name: sample-app-node-api-configmap
41 key: public_node_api_db_table
42 - name: PUBLIC_NODE_API_PORT
43 valueFrom:
44 configMapKeyRef:
45 name: sample-app-node-api-configmap
46 key: public_node_api_port
47
48 - name: PRIVATE_NODE_API_DB_USERNAME
49 valueFrom:
50 secretKeyRef:
51 name: db-connection-secret
52 key: PRIVATE_NODE_API_DB_USERNAME
53 - name: PRIVATE_NODE_API_DB_PASSWORD
54 valueFrom:
55 secretKeyRef:
56 name: db-connection-secret
57 key: PRIVATE_NODE_API_DB_PASSWORDNotes on the above:
namespace: sample, ensures this deployment and pods from it are in the sample namespace.name: sample-app-node-api-deployment, is the name that the deployment is shown in the kubectl commands. Pods are commonly named with a random string after the name of the related deployment:sample-app-node-api-deployment-77459cf885-gdtq4.labels.app: sample-app-node-api, add the label this deployment can be internally referred to, needed later when we set upservices.replicas: 1, is the number of pods that should be active at any one time. In local development dealing with a single pod is helpful, but in higher envs it should likely be 2+ minimum to allow for secrets to be rolled out and restarts as well as pods moving to other nodes.spec.template.spec.container.image: kubernetes-samples-sample-node-api, refers to the image tag that was tagged to the build container from the docker build step.spec.template.spec.container.imagePullPolicy: Never, is good for local development, it makes sure that kubernetes never looks to a remote registry for the container and only uses what is in the local image cache. When building locally with rancher desktop the images are placed into that cache and allows users to not have to always push to a remote image repository. Beyond the local environment you'll always build, tag and push a docker container to a remote repository (even if it's private).spec.template.spec.container.ports.containerPort: 3000, is the port the container will be listening on, this needs to match the port within the application.spec.template.spec.container.env, this entire block defines environmental variables that will be available to the container including secrets. Some of these env vars pull from config map objects and others pull env vars from a secret object.limits,Using
kubectl top pod -n samplewe can see what the current workload is:
and what the usage is for each of the pods under minimal load is:
pod:
sample-app-nginx-web-deployment-5fbc96b498-wlm5wshows CPU:0mand memory of2Minginx is a relatively low consumption resource and its current base configuration has minimal overhead
we'll set the requested CPU to
1mand max to4mwe'll set the requested memory to
3Miand the max to6mi
pod:
sample-app-node-api-deployment-66d8f9d56-9tz5fshows CPU:1mand memory of14Mi- 1. Node apps can have a much higher burst of resources so we'll have more differences in the limits we set. 2. we'll set the requested CPU to
2mand max to10m3. we'll set the requested memory to24Miand the max to48mi
Are these proper limit values? Well, it depends on the env and the kinds of usage that is only really observed with proper application load testing is needed to make sure that the values are set appropriate also including what kinds of caching strategies are in place (A CDN in front of a node API server fetching long lived DB requests from redis in front of Postgres is going to have much lower node resource needs than one that fetches all the way back for every request). If you set the limits too low and then start seeing eviction notices or pods responding then these will need to be increased. Alternatively they could be set too high and then not use all the resources allocated to the cluster.
probes,spec.template.spec.container.startupProbe:A pod can be started to take on workloads. This is used to check if your application is ready to take on work, perhaps the POD is not ready as the app is running, but a dependent service is still starting up. If the pod isn't ready in x seconds, restart it to give it a chance at starting successfully. Typically these can be longer tolerances compared to readiness or liveliness.
spec.template.spec.container.readinessProbe:Health checks ensure that the pod is able to deliver expected workload. A readiness check might ensure that a required DB connection is available or that the app has access to a file. If the pod passes readiness additional time is given for the pod to become healthy.
Depending on the app it may make sense to have different liveliness, readiness, and health checks as well as set values for how long those should be.
Helpful commands:
kubectl get deployments -n sampleto get all the deployments in the sample namespacekubectl describe deployment [deployment name] -n sampleto get details on the deployment with the name[deployment name]
Alternate workload types
We've been working on a web application or API. One could also leverage deployments for keeping code running that listened for events as the input that triggered some work to be done (microservices). If you are looking for a workload that runs every X hours, CronJobk8s objects are like Deployments, except one can specify how often the code runs.
Service
Congratulations, we've got code running and deployed, how do we get to it? With a service. Services tie changing deployments, pods, and replicasets through networking.
Types of services
ClusterIP Use services of type ClusterIP exposes the service within the cluster with an internal IP. This is great for setting a service to a database or backend API that should only be accessible by UI deployments.
NodePort Use services of type NodePort to make a service accessible outside the cluster. Typically used for training, demos, or temporary applications as they randomly remap ports.
LoadBalancer Use services of type LoadBalancer to get assigned a fixed external IP and create a LoadBalancer to split traffic across multiple replica set pods if they exist. This is great for services like external facing APIs that need to be accessed by an external frontend and have traffic spread across multiple pods.
1#sample-app-node-api-deployment-66d8f9d56-mtbvx (name changes with each deployment)
2apiVersion: v1
3kind: Service
4metadata:
5 name: sample-app-node-api-service
6 namespace: sample
7spec:
8 type: LoadBalancer
9 selector:
10 app.kubernetes.io/name: sample-app-node-api
11 allocateLoadBalancerNodePorts: true
12 ports:
13 - name: http
14 port: 3000
15 protocol: TCP
16 targetPort: 3000
17Port forwarding
Related to pods, deployments, and services; you can temporarily to check that your pod is working, your deployment is working and then that the service is working as expected you can try these individual commands and then load http://localhost:8888/config to make sure you get the response you are looking for.
kubectl port-forward pod/sample-app-node-api-deployment-77459cf885-p86rt 8888:3000 -n sampleMost reliable since we are targeting a specific pod.
Podnames change so it needs to be looked up oftenkubectl port-forward deployment/sample-app-node-api-deployment 8888:3000 -n sampleVery reliable if there's only one pod in the deployment.
Deploymentnames don't change so you can reuse the name in commands.kubectl port-forward service/sample-app-node-api-service 8888:3000Servicenames do not change, so it doesn't need to be rechecked after deployment
Ingress
Exposing a web endpointpermanently requires ingress. Locally we'll leverage Traefik to expose API end points and route them to a service.
1# application/sample-node-api/_devops/kubernetes/06-sample-node-api.ingress.yaml
2apiVersion: networking.k8s.io/v1
3kind: Ingress
4metadata:
5 name: sample-node-api-ingress
6 namespace: sample
7spec:
8 ingressClassName: traefik
9 rules:
10 - host: api.node.sample.local
11 http:
12 paths:
13 - pathType: Prefix
14 backend:
15 service:
16 name: sample-app-node-api-service
17 port:
18 number: 3000
19 path: /
20Here the sample-node-api-ingressobject in namespace sampleuses the ingress class traefikto make an ingress controller and creates a rule to map api.node.sample.localto the service sample-app-node-api-serviceon port 3000 without doing any URL rewriting/mapping: just /
Another option is using ingress-nginx requires installing it first, not included in this series.
DNS
Once the app is running in a containeron a podbecause of a replicasetfrom a deployment, the serviceis connected, and ingressis in place to map traffic to the container. Why doesn't a browser resolve http://api.node.sample.local/? DNS.
Running Rancher Desktop locally? Edit your hosts file, keeping in mind that if you are using WSL2 on windows you may need to edit multiple.
Here's the /etc/hosts entries on OS X for me:
1127.0.0.1 api.node.sample.local
2127.0.0.1 sample.local
3127.0.0.1 vault.shared.sample.localRunning Kubernetes on a different machine? VM? You may need a hosts entry or a setting on a router or a custom DNS server to resolve a URL to your Kubernetes instance.
Use a command like nslookup on OS X
1nslookup api.node.sample.local
2To verify that the name is mapped back to an IP.
Custom Resource Definitions (CRDs)
Across the lifetime of Kubernetes, various tooling has added new features through custom resource definitions.
Resilience
Kubernetes managing application deployment and keeping an ever vigilant watch over the health of containers is the point of the tool, but using Kubernetes doesn't mean your application(s) are untouchable.
One still needs to have numerous resilience considerations including:
Disaster recovery and business continuity: to ensure that your cluster isn't completely located in one region/zone and in case of a critical failure workload can be scaled up for in another area
High availability of sub systems of an application: having a database is great, but having multiple instances that are replicating data back and forth is key to prevent data loss
Alerting and Monitoring: which can be tied into Kubernetes, but takes additional effort to have stronger visibility into how your cluster is running
Each of these topics hosts a wide range of knowledge to learn up on.
Performance
Performance of the cluster and of the workloads that run upon it needs to be considered when building.
Do you need databases to have affinity to nodes with SSDs instead of HDDs? Are the pods getting the CPU and memory resources they need? Are there too many side cars bloating the pods?
The performance of the cluster doesn't stop there, it ultimately needs continual review and grooming, it's not a once and done task.
Also local developer performance must also be considered, to ensure that the local containers have enough resources to run effectively.
kubectl top nodesto understand how much of your nodes CPU and RAM are being used (helps to understand cluster node usage)kubectl top pods -n sampleto understand how much each of your pods CPU and RAM are being used in the sample namespace (helps to understand workload usage)kubectl get pv,pvc -n sampleto get all the persistent volumes and persistent volume claims for the namespace sample (helps in tracking down storage)kubectl get events -n sample --sort-by='.metadata.creationTimestamp'to get the latest events in the namespace
Security
There's a whole series of topics in Kubernetes security and great resources and articles and courses towards certifications that all focus on security.
Least amount of access
One of the largest issues is that clusters are built with everyone having access instead of locking down users to namespaces and having Role Based Access Control (RBAC) in place with the correct service accounts with limited access.
Setting these up correctly needs proper implementation.
Planning what is exposed
Just because you can add ingress objects and expose every service inside the cluster, doesn't mean you should.
Consider these use cases:
The UI that an end user uses (should be exposed)
A middleware API and end user uses (needs to be exposed for the UI to connect with)
A domain API the middleware API connects to (should not be exposed with ingress but used as a service internally)
The Vault UI for managing secrets (should not be exposed externally, but internally to a subset of users)
The Vault API for managing secrets (should only be available internally)
Certificates
One thing this series doesn't touch upon (yet), is certificates. From a security perspective encryption is critical throughout a system while data is in motion or at rest. Part of that includes having the right certificates for each of the services.
Setting up certificates typically requires purchasing a domain, as this guide focuses on low barrier to enter we can still point out some excellent options:
Certbot is one tool to auto renew certs with Let's Encrypt and here's some articles to get started with.
When purchasing/managing DNS records it's good to get a provider that allows for HTTP-01 and DNS-01 level challenges. AWS Route-53 does it, so do others, but not all do; so it's worth checking as moving a domain is typically not hard, but not fun.
Another tool cert-manager (github) is also worth evaluating for your needs (support for Kubernetes and OpenShift), which also has supporting, articles.
Zero Trust
Another aspect of security is to consider zero trust. Early on applications were considered secure if they had a strong walled garden approach. Once you get your key past the wall you can do whatever is needed. As attackers may attack through a less secure side channel and use privilege escalation to laterally move through a network requiring all requests to be confirmed becomes necessary. One then has to have the set of keys to move around the different gates within the garden reducing the blast radius of an attack.
This kubernetes sample doesn't take on authentication or authorization topics as that's left to the application to handle and will be wildly different per application. Some might use SAML, identity management like Identity Server, or OAuth providers.
Wrap up
We now have an understanding of the Kubernetes objects that we've used to deploy our application. We've gotten our application running in kubernetes by building (_devops/build.sh), deploying (_devops/deploy.sh) and configuring secrets (_devops/configure.sh). Let's continue to alter this to handle multiple environments with Helm.
Moving along
Continue with the sixth article of the series: Managing Secrets with Vault
This series is also available with the accompanying codebase.
Stuck with setup? Refer to full project setup instructions.
Done with the series? Cleanup the project workspace.